First, the user emphasized that HTML tags must remain intact. So I have to make sure not to change any tags, their order, or attributes. Also, placeholders like [[IMG_BASE64_PLACEHOLDER]] should stay exactly as they are. I need to check if there are any such placeholders here. Scanning through, I don't see any, so that's good.
Next, the translation must be done paragraph by paragraph and sentence by sentence without omitting anything. That means I can't skip any part of the original text. I'll have to go line by line, translating each section carefully.
No extra explanations or prompts are allowed. So the final output should just be the translated text with HTML tags, no additional comments. Also, it shouldn't be in markdown, html, json, etc., just plain text with the same structure.
The translation needs to be natural in Japanese, avoiding literal translations. I need to ensure that the sentences flow naturally and follow Japanese grammar rules. However, some terms might be technical or proper nouns, so those should stay as they are unless specified otherwise.
Another point is maintaining the HTML structure. Only the text inside the tags should be translated; the tags themselves remain unchanged. So if there's a
tag, I translate the content within it but keep the tag as is.
No buttons or interactive elements should be added. The user mentioned that the result shouldn't have any unrelated buttons or instructions, so I need to make sure not to introduce those.
Language mixing is prohibited except for proper nouns. So if there are any English terms like "STEM" or URLs, they should stay in English. Also, check for any accidental language mix-ups.
Finally, only the translated text should be returned without any extra content. No explanations, no additional text—just the Japanese version of the provided content with the same HTML structure.
Now, starting with the first line: "Clever Kids University: I Can Read - La revolucionaria aplicación bilingüe". The title has a Spanish phrase "La revolucionaria aplicación bilingüe". Since it's part of the title, maybe keep the Spanish term as is, but check if the user wants it translated. Wait, the user said to translate the content, so I should translate that part. However, sometimes titles are kept in the original language. But according to the rules, I need to translate everything except placeholders and proper nouns. So "La revolucionaria aplicación bilingüe" would be translated as "二言語アプリケーションの画期的な革新".
Next paragraph: "Presentamos Clever Kids University: I Can Read..." The entire paragraph needs to be translated. Make sure not to change any tags, but since there are no HTML tags here except the heading, which is part of the content, I need to check if the user included any. Wait, looking at the original text, the first line has "Clever Kids University: I Can Read - La revolucionaria aplicación bilingüe" followed by a section with "### Cómo comenzar". The "###" might be markdown headers, but the user said not to output in markdown. However, the user's instruction says that the translation should have HTML tags. Wait, the original content provided doesn't have any HTML tags except maybe the headings? But the user didn't provide actual HTML code. Maybe the user is referring to the structure as per their own system. Hmm, this might be confusing.
Wait, looking back at the user's instruction: "保持 HTML 标签结构不变,仅修改标签内文字。" So if there are any existing HTML tags in the original content, they should remain. But in the provided text, I don't see any actual HTML tags like
, etc. The only possible ones might be the ### which are markdown headers, but the user said not to output in markdown. However, since the user says "保持 HTML 标签结构不变", maybe they expect that if there were HTML tags, we should keep them. But in this case, the original content doesn't have any, so perhaps it's just plain text with sections marked by ###.
But the user might have intended for the translation to maintain whatever structure is present. Since there are no actual HTML tags here, maybe I can proceed without worrying about that part. However, if the original content had some tags, like
or
, they should be kept as is. But in this case, it's just plain text with headings using ###.
This might be a bit of a problem. The user's instruction says to strictly follow the rules, so I need to make sure that any existing HTML tags are preserved. However, since there are no actual HTML tags here, maybe that part is not applicable. But to be safe, I'll assume that any markdown-like structure (like ###) should remain as they are, but the user said not to output in markdown. This is a bit conflicting.
Wait, the user's instruction says: "禁止输出为 markdown、.html、.json 等文件格式,只能为带 HTML 标签的纯文本。" So the output must be plain text with HTML tags. But if the original content doesn't have any, then there are no tags to preserve. So maybe in this case, since there are no HTML tags, I just translate the text as is, keeping the structure (like ###) but treating them as part of the content.
But the user might be expecting that if there were HTML tags, they would be preserved. However, given that the original content doesn't have any, perhaps it's okay to proceed without them.
Moving on, translating each section carefully. For example, "Necesitarás un inicio de sesión o un Código Secreto para empezar." becomes "ログインまたはシークレットコードが必要です。"
Also, URLs and email addresses should remain in English. For instance, "www.myf2b.com/register/find" stays the same.
Proper nouns like "Clever Kids University", "Footsteps2Brilliance", "Model Innovation City™" should stay as they are, but check if the user wants them translated. The instruction says to keep proper nouns as is unless specified otherwise. So these remain in English.
I need to be careful with technical terms like "STEM" which is an acronym and usually remains in English. Also, terms like "fonética" would be translated to "音声学" or "発音", depending on context.
Another point: the user mentioned that the translation should avoid being too literal. So I need to make sure the sentences are natural in Japanese. For example, "Los buenos lectores se convierten en estudiantes exitosos para toda la vida!" becomes "良い読者になることは、人生を通じて成功する学生になることを意味します!"
I'll proceed section by section, ensuring that each part is translated accurately while adhering to the rules. After translating, I'll review to check for any missed tags or structure changes, and ensure no extra content is added.
Clever Kids University: I Can Read - 二言語アプリケーションの画期的な革新
Clever Kids University: I Can Readをご紹介します。これは、英語での読解力と書字力を教えるための革新的な二言語アプリです。スペイン語にも対応しています。良い読者になることは、人生を通じて成功する学生になることを意味します!このアプリは、週単位で整理された体系的な指導によって、読解力における堅固な基盤を築きます。
開始方法
ログインまたはシークレットコードが必要です。あなたの地域でのアクセス可能なパートナーがいるかどうかを確認するには、www.myf2b.com/register/find を訪問してください。あなたの都市で公平な識字プログラムを開設したい場合は、[email protected] までお問い合わせください。
受賞歴のあるコンテンツ
Clever Kids Universityは、Association of American PublishersやNational Parenting Publicationsなど、他にも多くの著名な賞を受賞したゲームとデジタルブックを提供しています。
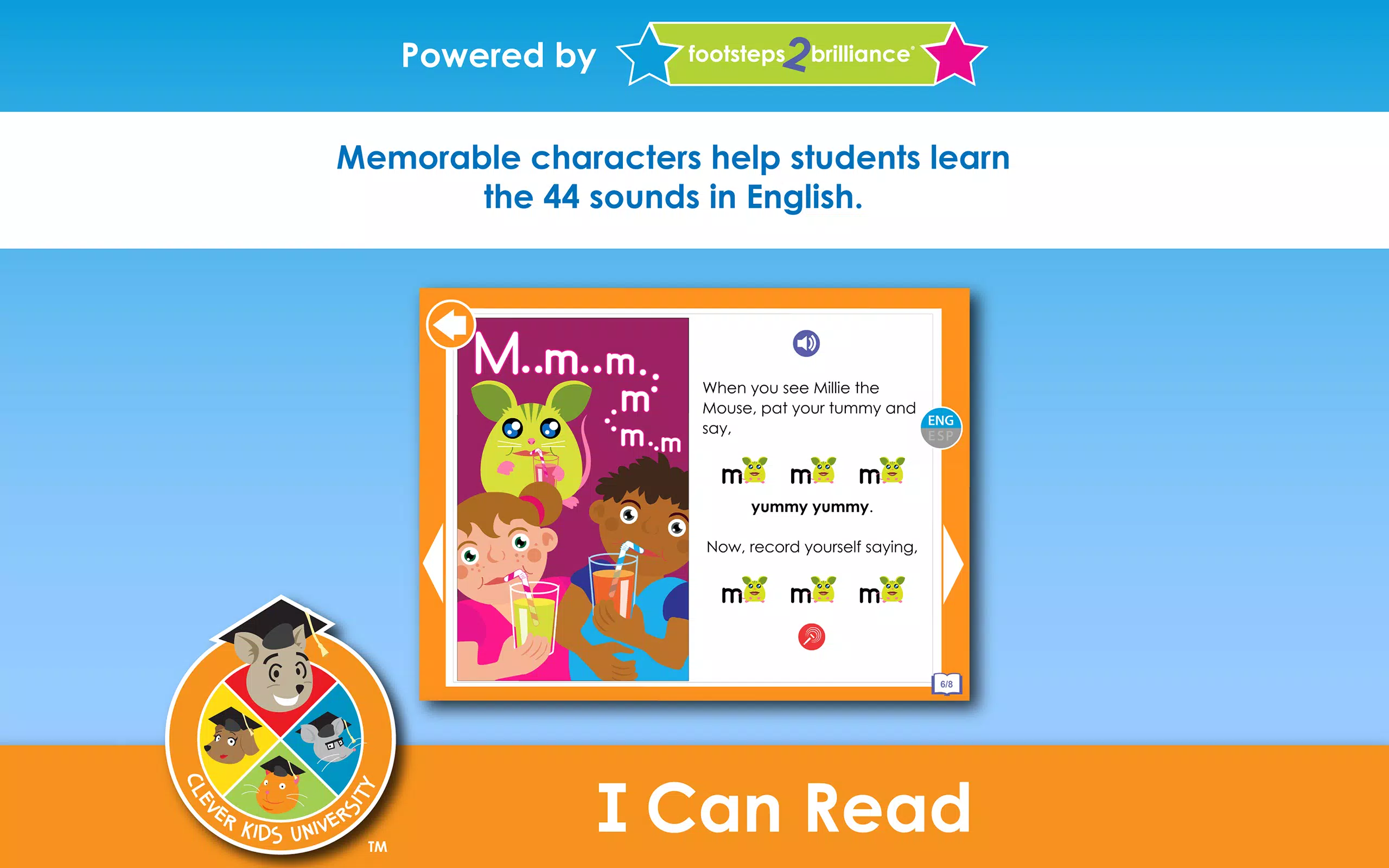
面白い音声教育
アプリには「Mega Mouth Decoder」の本や曲が含まれており、英語の44種類の音を認識および発音するのに役立つ記憶に残るキャラクターが登場します。それぞれのキャラクターはその名前、物語、性格を通じて特定の音を忘れられない形で強調しています。
レベル別の解読可能な本
毎週、生徒たちは新しい発音スキルを使ってサムと友達に関する本を読みながら録音します。
書き取りに重点を置いたバランス型アプローチ
私たちは子どもが読む力を学ぶために書く必要があることを知っています。そのため、生徒は本の内容について絵を描いて書きなぐります。さらに、自分たちで作成した本のバージョンを作成・公開・電子メールで送信することもできます!
STEMに関する読みと書き
発音に加えて、毎週高関心度のSTEM(科学、技術、工学および数学)の本が提示されます。これにより、事前知識、理解力および語彙力を養います。
インターネット接続なしで動作
アプリとコンテンツをダウンロードした後は、インターネットに接続しなくても使用できます。再び接続すると進捗状況が同期されます。プライバシーポリシーについては、http://www.footsteps2brilliance.com/privacypolicy/ を参照してください。
インテグレートされたモチベーションシステム
このアプリは保護者と子供がそれぞれの成果を祝うことを容易にします。新しい音や本を習得したごとに証明書を獲得し、完了したアクティビティに対してコインを取得し、アプリを使用した毎日ごとにスターを獲得できます。
Footsteps2Brillianceについて
2011年から、Footsteps2Brillianceは教育格差が生じる前にそれを埋める活動を行ってきました。私たちは教育ソフトウェアの開発者から、米国の学生・家族・地域社会にポジティブな影響を与えている運動のリーダーへと進化してきました。当社のModel Innovation City™モデルは学校、家族、地域を動員し、小学校3年生における学業準備および読解力を向上させています。このモデルをあなたの地域で実施したい場合は、[email protected] までお問い合わせください。